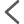申明:本教程仅供学习参考,未经他人允许请勿擅自采集,否则后果自负。

以采集某问答网站为例,我们先右键查看网页源代码,去看看它的源码:
定位标题位置,可以直接Ctrl+F搜索标题内容查到位置,代码简单的很好翻:

因为标题是被h1标签包住的,所以我们这里用h1,如果是<p>、<span>、<div>等,换一下就行。
所以这个网站的标题规则可以写成:
<h1>([\s\S]+?)</h1>
接下来定位正文内容:
因为这个内容是被div包住的,这里需要注意,建议只用写最最近的div样式就行。
所以内容规则我写成:
<div class="content markitup-box">([\s\S]+?)</div>接下来我们设置发布用户及板块等即可完成采集任务。
建议自己试一试,但是不要一次性采集太多内容,以免出现不必要的麻烦,每次100篇为宜,服务器不错的话,可以尝试采集更多。
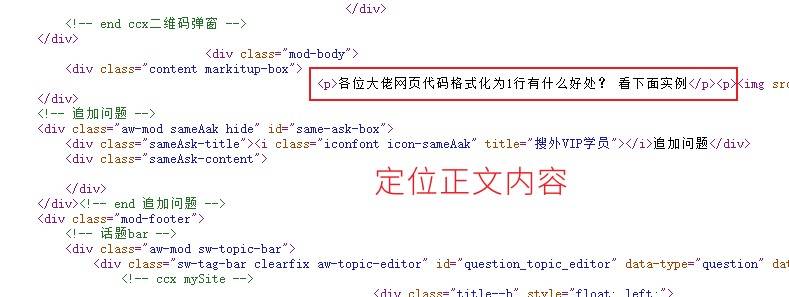
采集后的内容不会在前台和板块中显示,但是在你设置的用户主页中可以查看。这个应该属于BUG,我之前提过这个,但是没有得到解决,希望在hadsky后期 中更新能修复这个问题。
老规矩,成功了记得回帖评论告知我!